日本萝莉
日本萝莉
新智元报谈
裁剪:裁剪部 HYZ
【新智元导读】OpenAI下一代模子——o3,重磅降生了!陶哲轩预言难住AI好几年的数学测试,它转眼破解,编程水平位于全球前200,在ARC-AGI基准中更是惊东谈主,突破所有这个词AI记录接近东谈主类水平,离AGI更近一步。
12天临了一天,OpenAI下一代推理模子o3真实出世了!

奥特曼、Mark Chen、任泓宇和ARC Prize基金会主席Greg Kamradt为咱们作念了先容
正如所爆料那样,出人意外的o3成为整场直播的「压轴菜」。
奥特曼显露,之是以跳过o2,是因为对伙伴的尊重,以及延续OpenAI一贯「起名极度差」的传统。
奥特曼的谜底也终于揭晓了——3个o
要知谈,距离9月o1的出世,才曩昔了整整3个月的时辰。o3的迭代速率,证明了Scaling Law似乎并未斥逐。

证据Keras之父发布的阐扬称,o3在低磋筹商模式下,每个任务需要破钞高达20好意思金,而在高磋筹商模式中每个任务则需要数千好意思元。
o3数学代码封神,离散o1
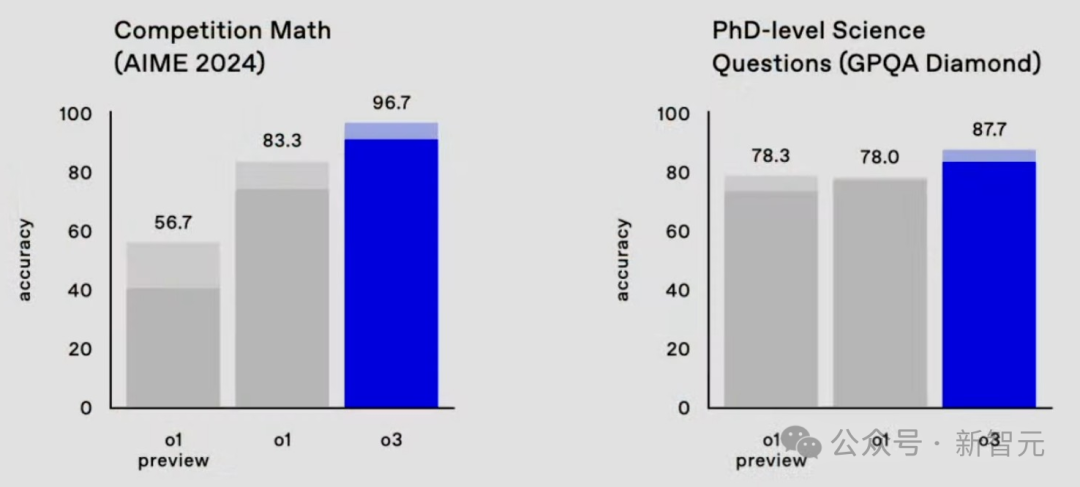
在多项基准测试中,o3再次刷新SOTA,就数学、代码、软件工程等领域,完满离散了满血版o1!
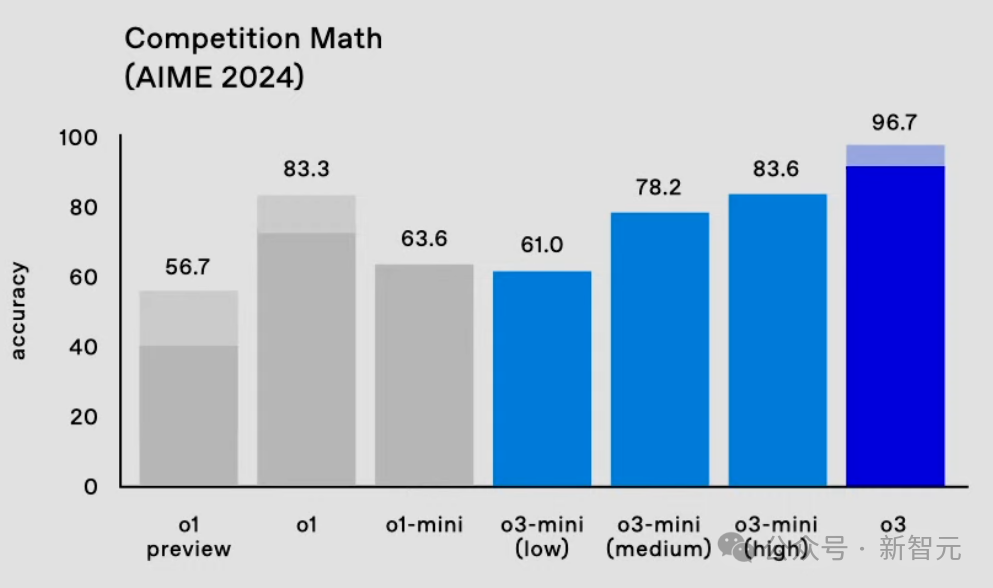
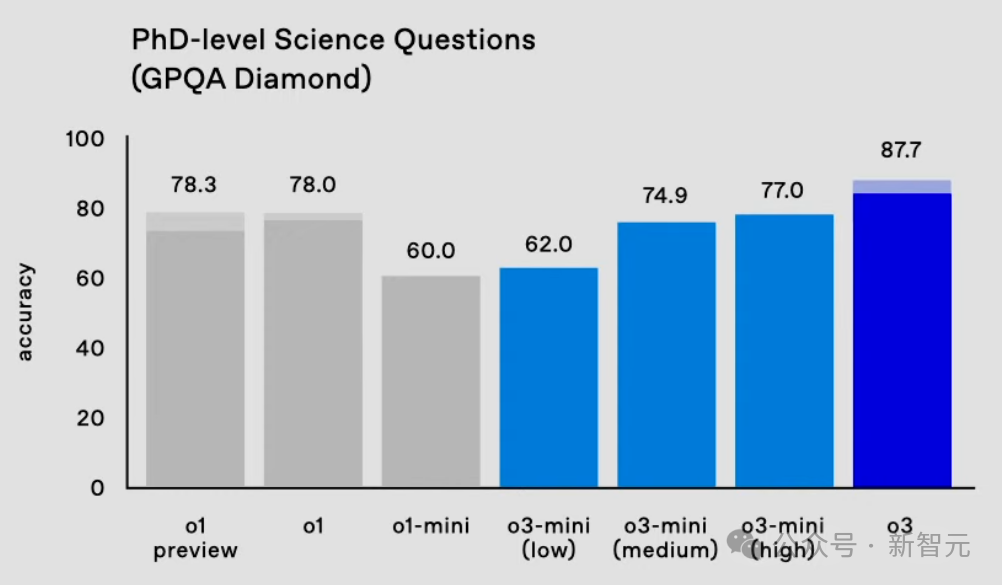
在AIME 2024数学竞赛评测中,o3取得了96.7%的准确率,性能平直飙升13.4%;在博士级科学问答基准GPQA Diamond上,o3准确率为87.7%,相较于上一代o1擢升9.7%。
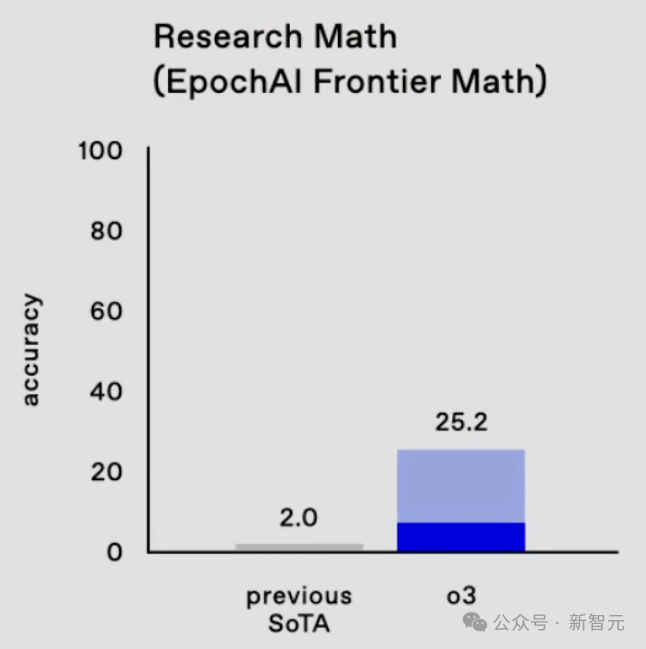
在本年11月Epoch AI发布的数学基准Frontier Math上,o3准确率高达25.2%。
这个基准中,今天所有这个词模子的准确率齐低于2%,但是在激进的测试时辰建造下,o3已经大致达到25%的准确率。
要知谈,联手60多位数学家出题的陶哲轩,曾合计这项测试大致难住AI许多年。
如今,这一说法又被OpenAI o3推翻了。

在软件工程SWE-bench Verified基准上,o3的代码性能从o1的48.9%狂飙22.8%,达到了71.7%。
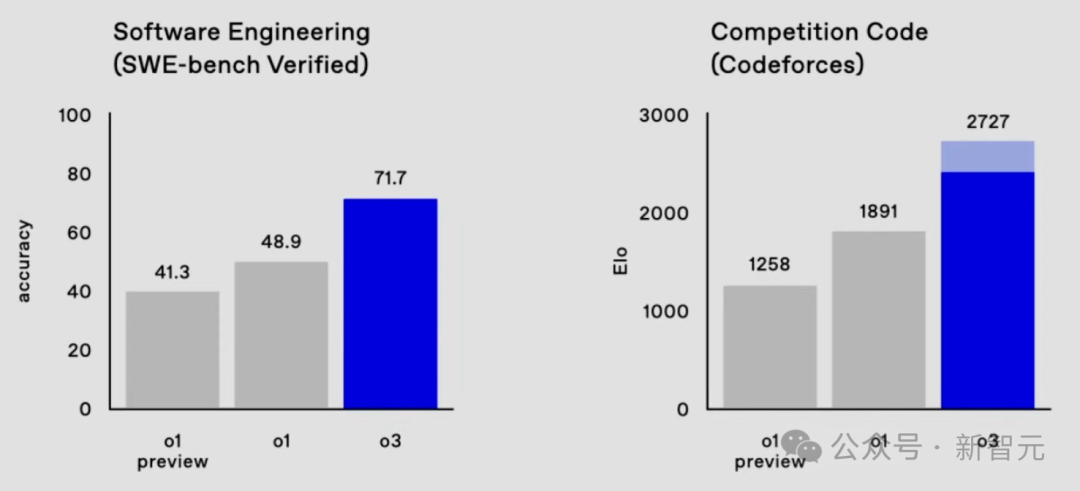
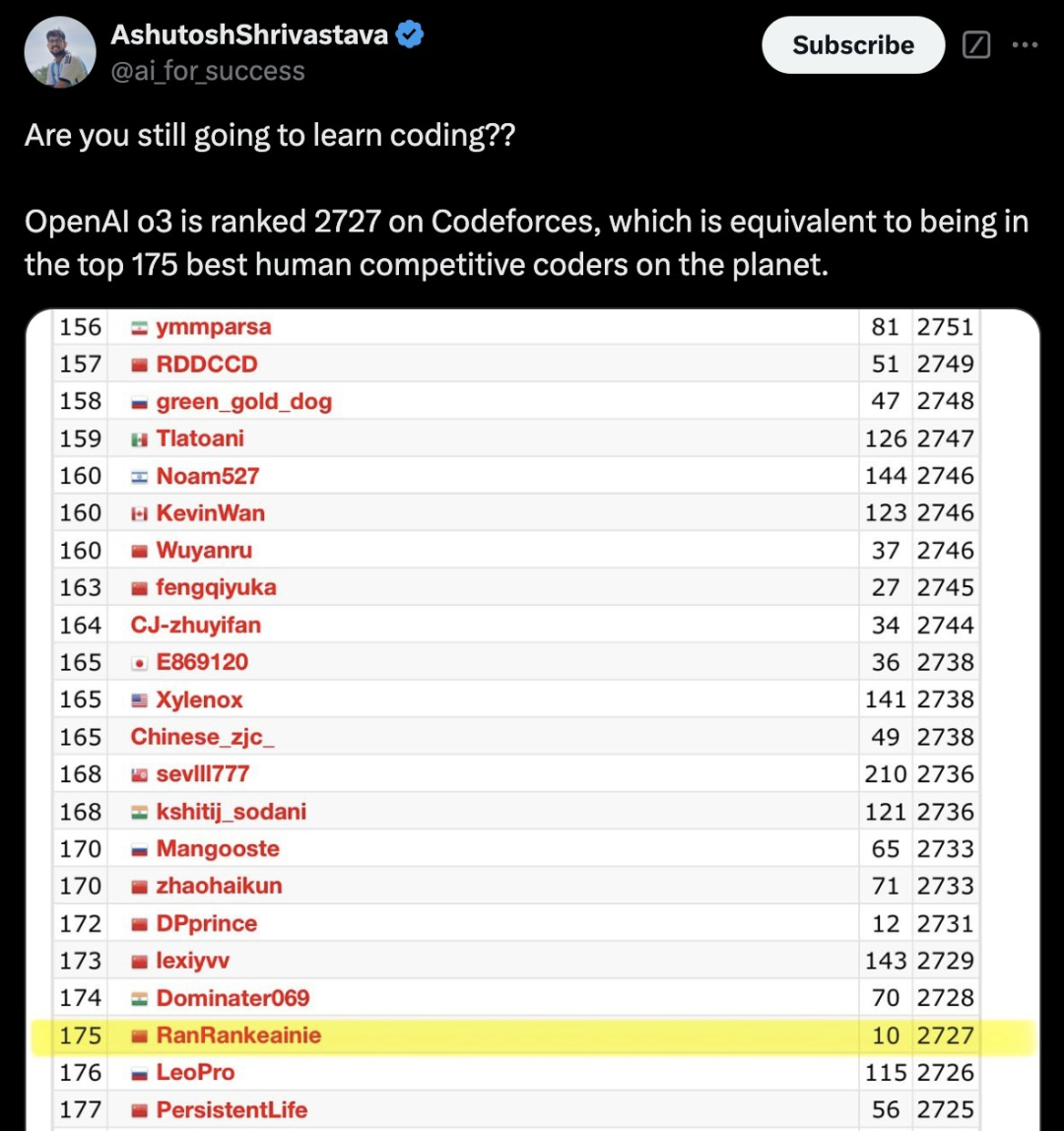
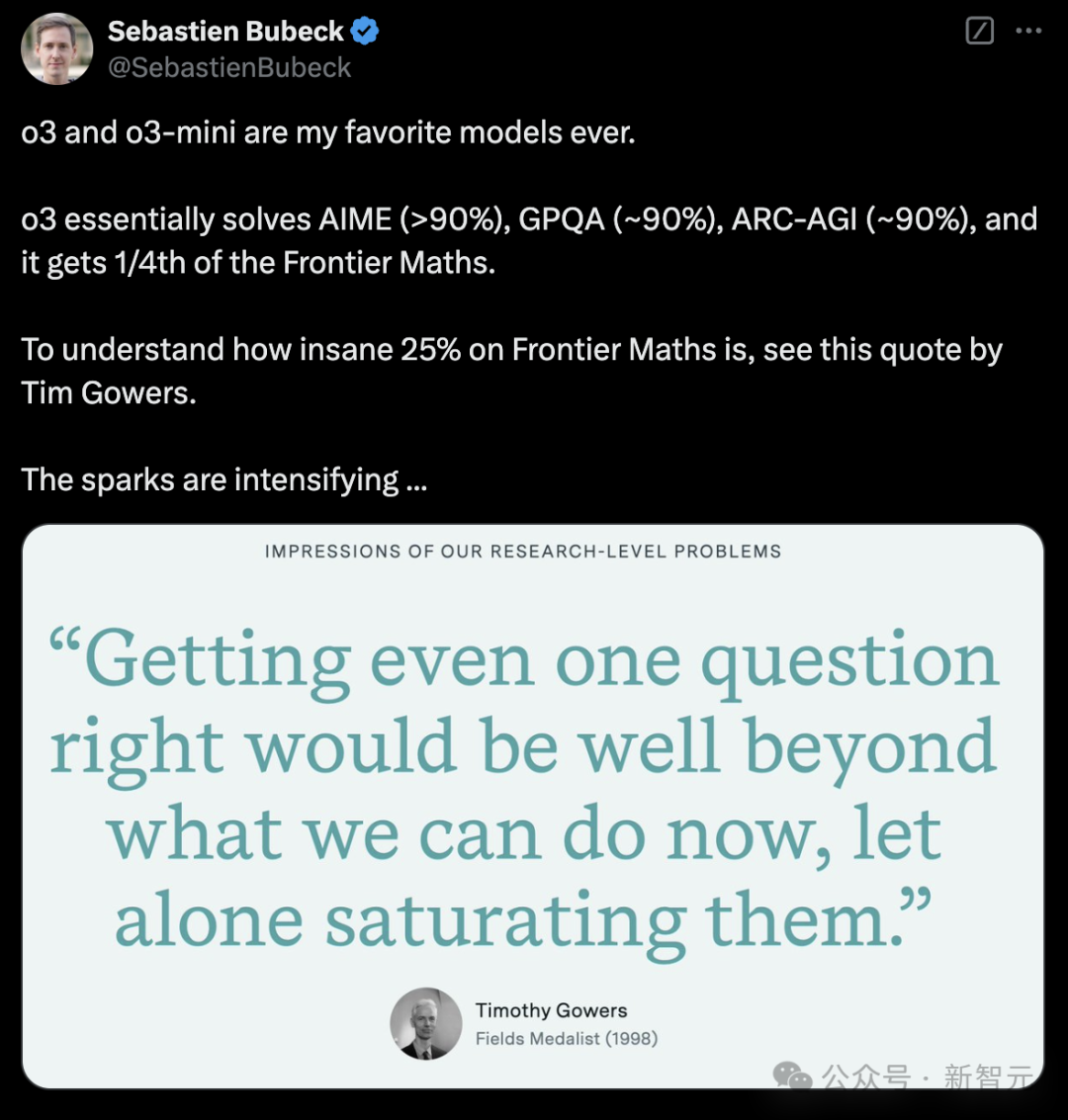
在Codeforces中,o3的Elo得分为2727,相较o1擢升了800多分。
这个发达,已经达到了International Grandmaster的水平,极度于位列175名的东谈主类选手。
致使,极度了OpenAI的照应高档副总裁。
除o3除外,o3-mini一样在数学、编码、博士级科学问答、函数调用等基准上,取得了新的突破。
它确凿界说了一种新的资本效益推理前沿。
奥特曼显露,这两款新模子将面向照应东谈主员测试,并期待异日尽快推出上线。
OpenAI照应科学家Sebastien Bubeck称,o3在Frontier Maths取得25%准确率,在菲尔兹奖得主Tim Gowers看来极其惊东谈主。这暗意了AI发展火花加快迸发。
网友纷繁显露,就在今天,咱们已经完了了AGI!

o3-mini:三种「念念考模式」,酌量越多才能越强
o3-mini算作o3系列的新成员,与o1-mini一样,将为开辟者带来高性价比的AI体验。
在编程才能评测中,o3-mini展现出惊东谈主的实力。
通过「自适合念念考时辰」(adaptive thinking time)机制,o3大致证据任务难度自动迂曲推理深度。
由此,它才完了了在代码生成方面超越了前代o1。更令东谈主钦慕的是,其运转速率和资本仅为o1的1/10。
o3-mini引入了三档念念考级别——低强度推理、中等强度推理、高强度推理,不错证据具体需求去迂曲模子的推理深度。
简言之,粗陋任务大致得到快速反应。而复杂的问题,模子则可开启更深度的念念考模式。

任泓宇(左)本科毕业于北大,后在斯坦福取得博士学位,负责o3-mini的西宾
具体来说,在Codeforces测试中,o3-mini的Elo评分跟着念念考时辰的增多,性能慢慢的到擢升。
致使,在中等强度念念下,o3-mini(medium)已经超了满血版o1的发达。
天然o3-mini(high)在高强度念念考下,仍过时于o3,但简直死别不大。
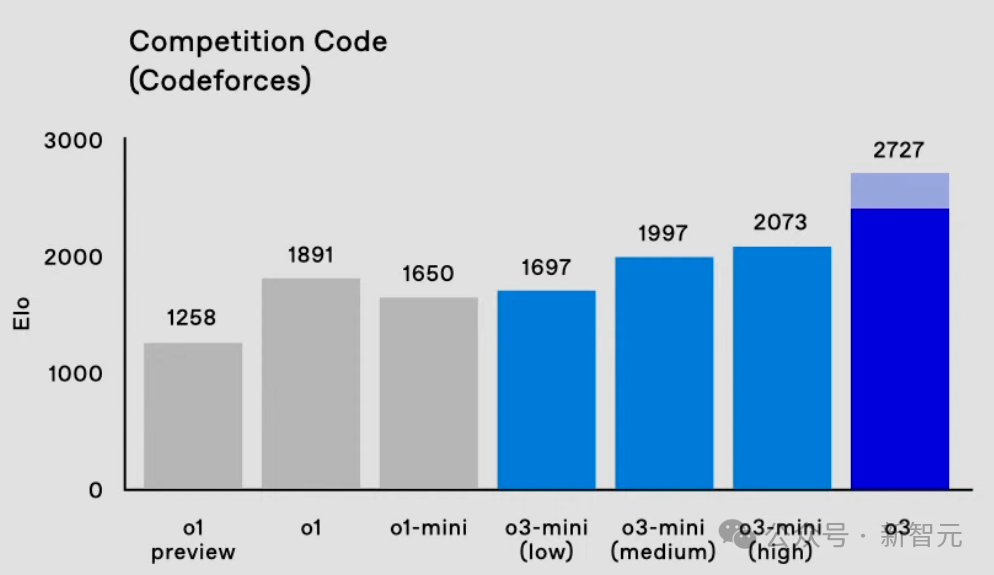
何况,在资本和念念考速率方面,o3-mini取得了超越o1-mini更好的性能。
哥也色
在演示中,照应者条款模子使用Python完了代码生成器和实际器。
启动之后,就像运转Python剧本一样,模子将在土产货启动一个管事器,带有一个包含文本框的UI。
然后咱们就不错在其中发出编码请求了,它会请求调用o3-mini API,它将料理任务,复返一段代码。
代码会保存在土产货桌面上,然后翻开末端自动实际代码。

以下,就是模子生成的代码,用时仅38秒。
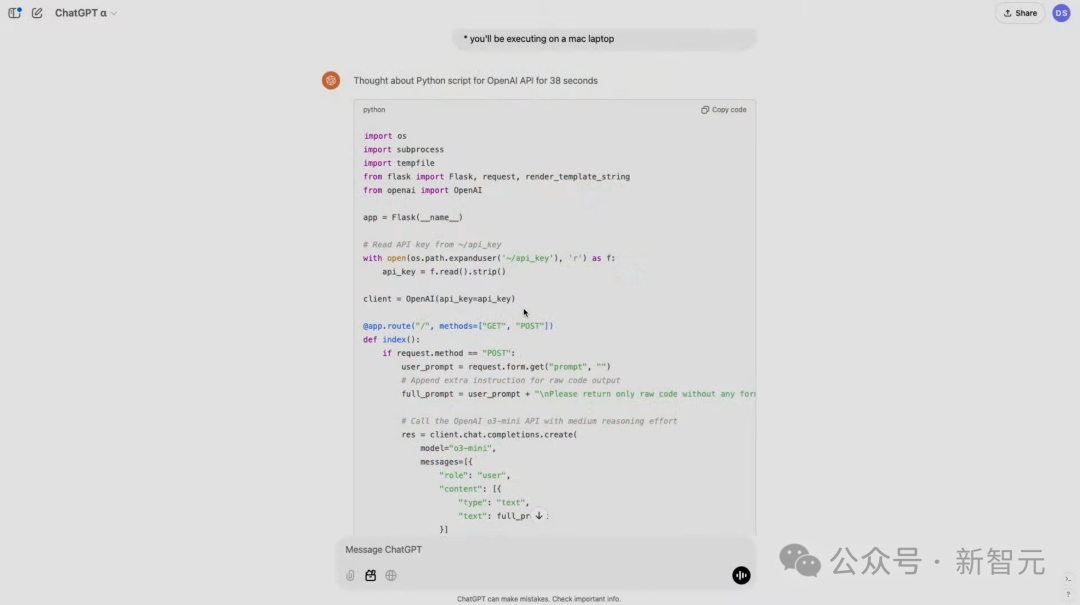
把代码复制粘贴到管事器上,并运转。
然后,便可取得对应的UI界面——一个文本框。
咱们不错在其中输入代码,比如打出OpenAI和一个立地数,它就会将请求发送到o3-mini(medium)。
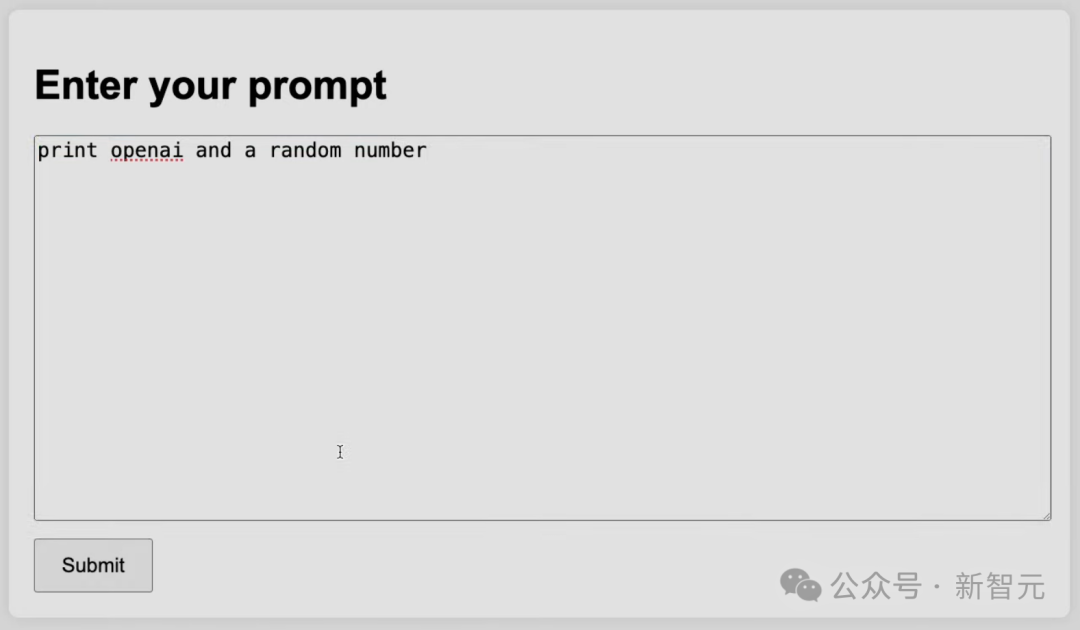
模子尽然按条款输出OpenAI,以及41这个数字。

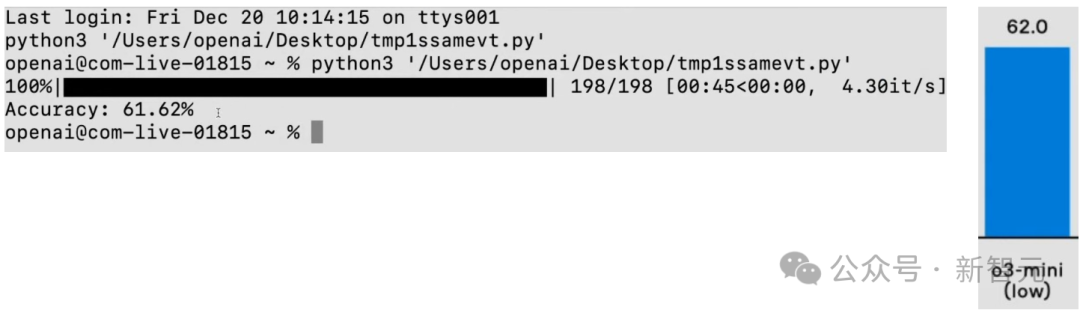
鄙人面这个任务中,照应者条款模子用较低的推理才能,来评估o3-mini在难度很高的GPQA数据集上的发达。
模子最初需要从该URL下载原始文献,然后需要识别哪些部分是问题,哪些是谜底,哪些是选项。临了,模子需要整理出所有这个词的问题,并尝试作答,剖判后果,临了进行评分。
模子的运转速率极快,因为它调用的是o3-mini,并使用了较低的推理酌量。

不错看到,后果为61.62%,和崇拜评估简直一模一样。
何况这个运转极快的低推理才能模子,所有这个词这个词评估经过只用了一分钟。
除了代码收成亮眼,o3-mini也展现出了超卓的数学才能。
在AIME 2024数学竞赛测试中,o3-mini(low)已经接近o1 mini的水平。
o3-mini(medium)以78.2%的准确率超越了o1(图中实心部分),而o3-mini(high)进一步擢升了性能。
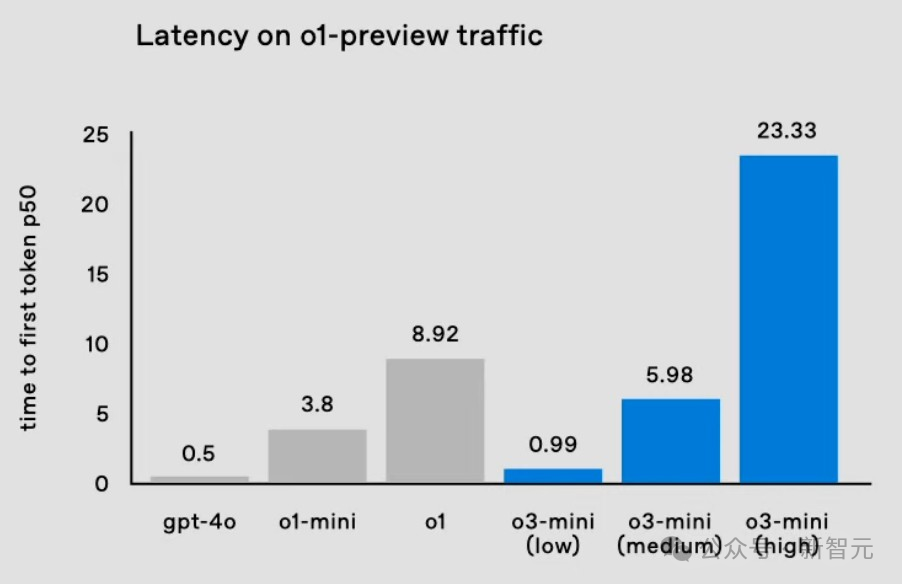
在延长方面发达,o3-mini(low)大幅裁减了延长,裁减至1秒内,失色GPT-4的即时反应。
o3-mini(medium)的延长比o1-mini快一半。
天然,OpenAI为了荒诞开辟者的需求,o3-mini提供了全套API功能,包括函数调用、结构化输出、开辟者音书。
更难能选藏的是,在这些功能上,o3-mini的性能不仅完满对标o1,并在多数评测中取得了更好的发达。
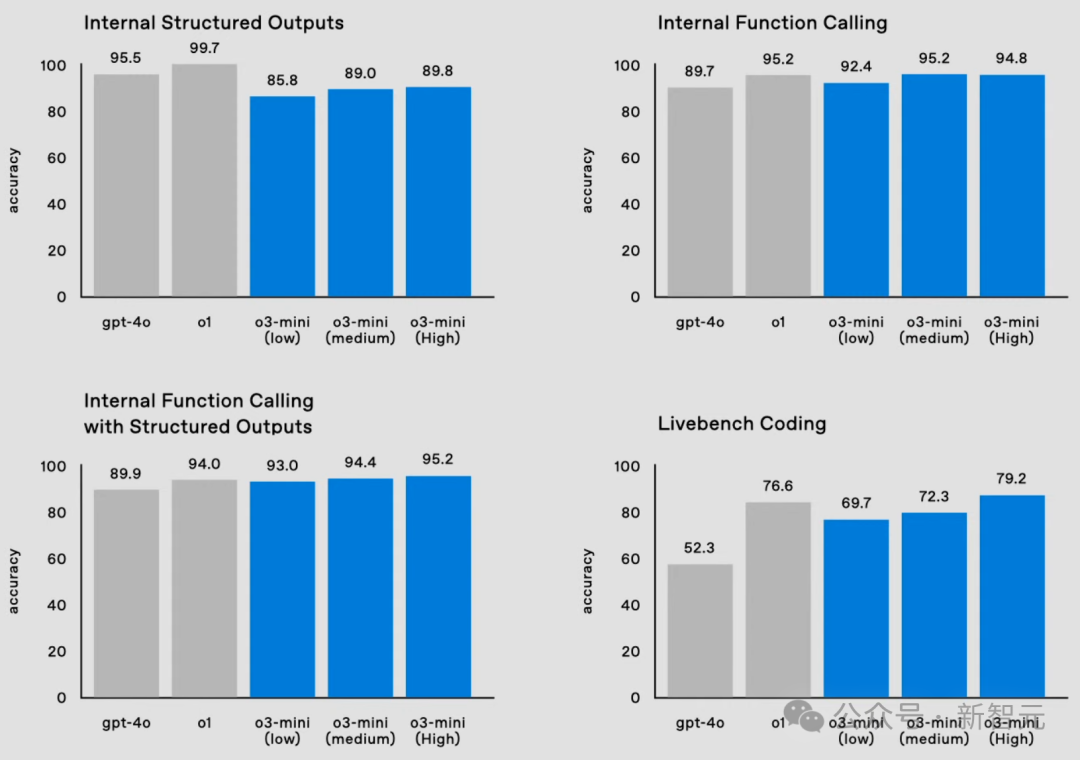
另外,在具有挑战性的GPQA数据集测试中,o3-mini展现出结实的性能,即等于在低强度念念考模式下,o3-mini(low)也达到了62%的准确率。
o3-mini暂时只向安全照应院灵通测试,不错平直在OpenAI网站中进行请求。

ARC-AGI基准
ARC Prize Foundation是一家非渔利组织,职责是在基准测试时候成为AGI的北极星。
他们的第一个基准ARC-AGI,是由Keras之父François Chollet于2019年在对于才能测量的论文中发表的,它在AI领域已经保持5年不败。

打败ARC-AGI的系统,将成为迈向AGI的抨击里程碑。
它的一起内容,齐是输入示例和输出示例,指标是了解变换的限定,猜出输出的示例。
而它的每项任务,齐需要不同的手段。
比如底下这个任务,凭东谈主类直观,很容易猜出临了一张图应该是什么,但AI很难集合。
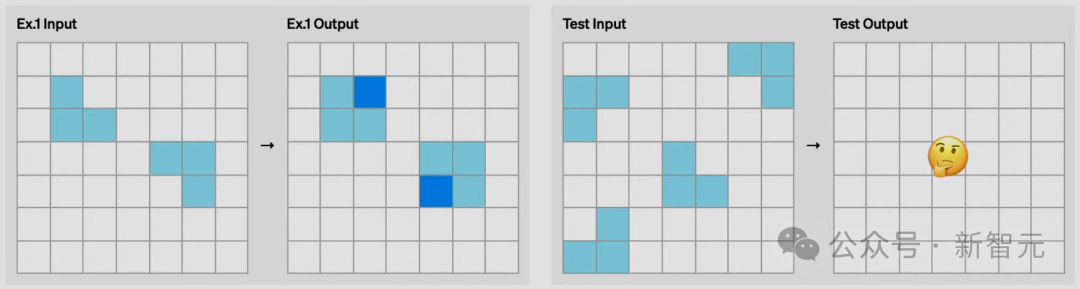
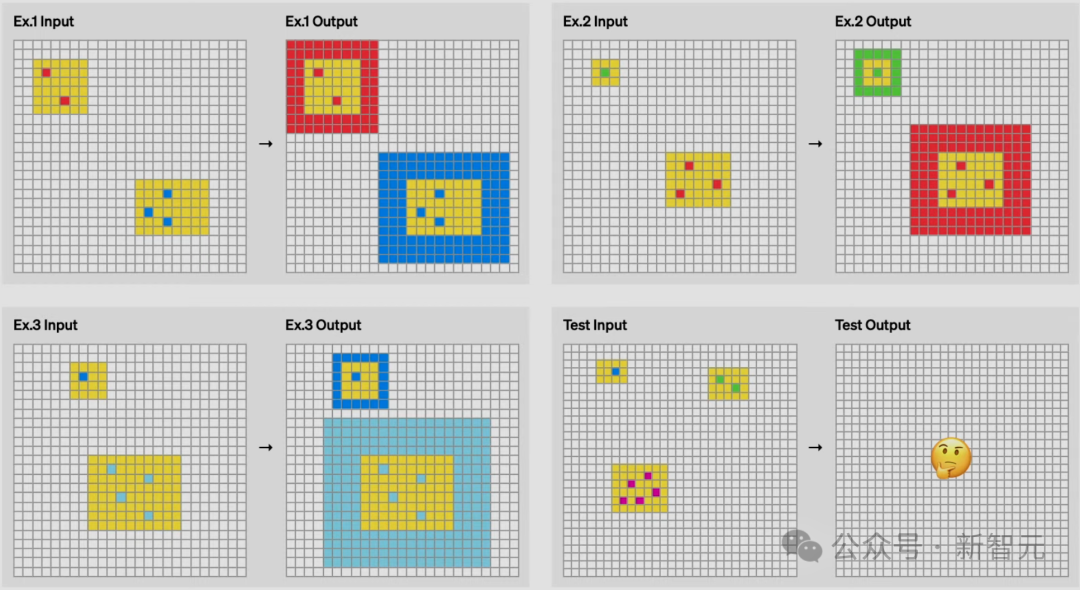
在这个任务中,则是需要在黄色方块中,数一下共有几许种神色的方块,然后用它创建一个边框。
照应者使用了两个ARC-AGI 数据集对 o3 进行了测试:
半特有评估:100个特有任务,用于评估过拟合
环球评估:400个环球任务
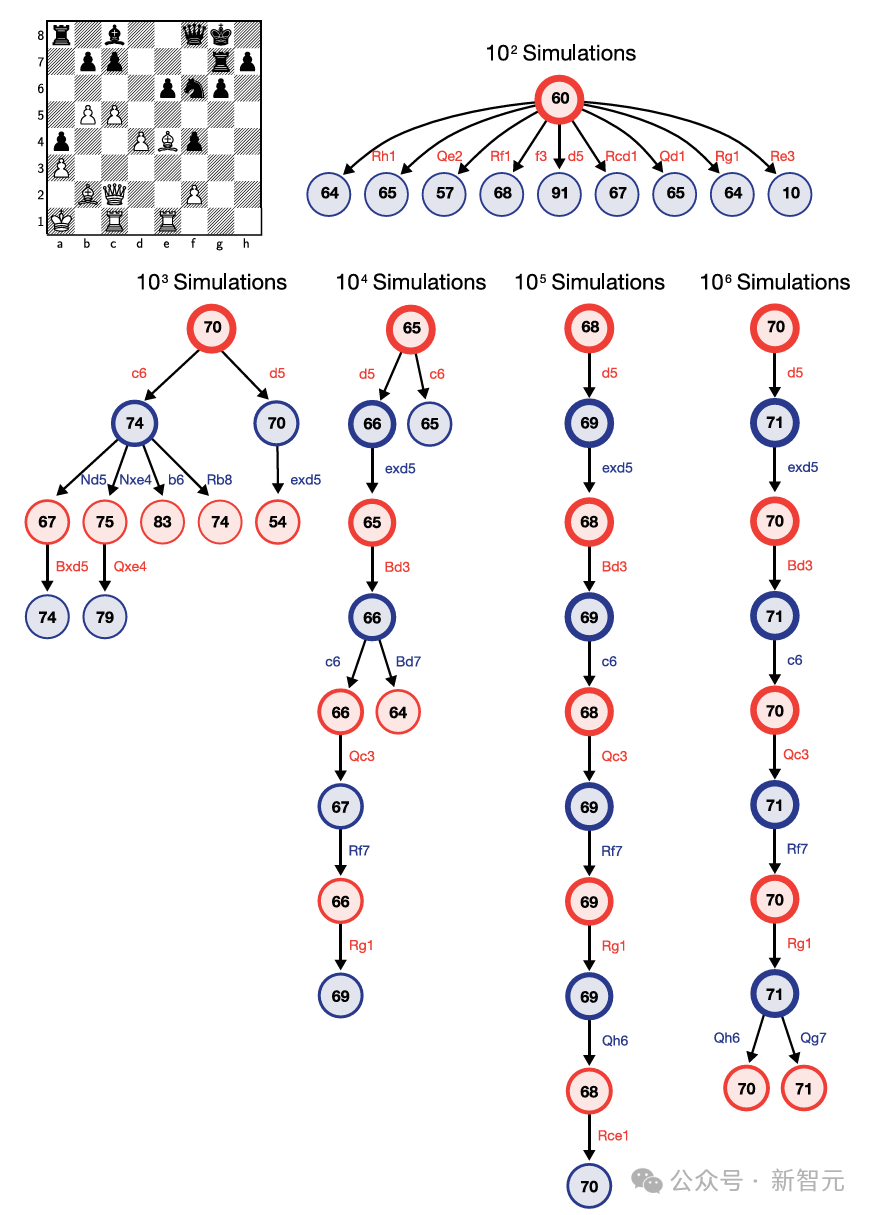
他们在两种酌量水平下进行了测试,样本领域分手为6(高效模式)和1024(低效模式,磋筹商是高效模式的172倍)。
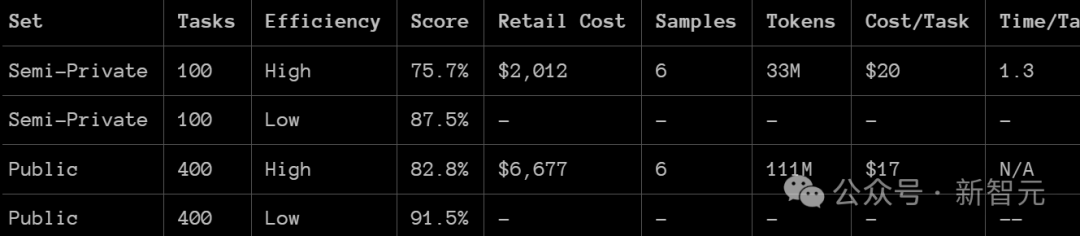
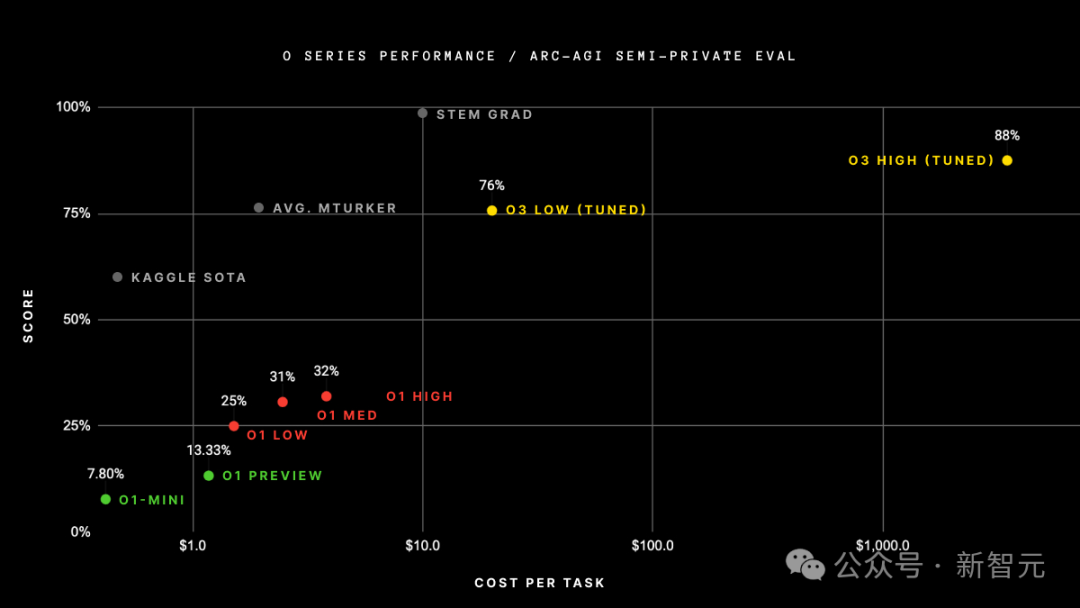
利弊的是,在这个基准测试中,o3在低酌量模式下,在半特有评估中的得分为75.7%;在高酌量模式下,得分为87.5%。
具体来说,高酌量模式下的得分为 75.7%,相宜 RC-AGI-Pub的预算为止(资本低于1万好意思元),因此在环球名次榜上排名第一。
低酌量模式下的得分为 87.5%,天然资本较高,但仍然标明在新任务上的性能跟着磋筹商的增多而擢升。
这点尤为抨击,因为东谈主类在该任务上的发达往往在85%的水平。
极度这一数字,就意味着达到了一个抨击的里程碑,因为此前从未有任何AI系统完了过这一成立。这标识着ARC-AGI领域的一个全新突破。
ARC Prize Foundation的主席显露,看到这些分数时,他结实到需要略略更正一下我方的寰宇不雅,修正对AI究竟能作念哪些事情的直观。
何况要知谈,现在还仅是AI的早期阶段,是以咱们就更需要ARC-AGI这样的经久性基准测试,来对进展进行评估和指导了。

OpenAI o3,还不是AGI
总之,这是AI才能的一次令东谈主骇怪且意旨要紧的跃升,展现了GPT系列模子前所未有的新任务适合才能。
要知谈,ARC-AGI-1从2020年GPT-3的0%擢升到2024年GPT-4o的5%,历时4年。
尽管资本较高,但o3的这些收成并不单是是通过在基准测试上哄骗暴力酌量得来的。
不错说日本萝莉,o3的性能不是一次渐进式的更正,而是一次确凿的突破,标识着AI才能比较此前的LLM局限性,完了了质的飞跃。
大致适合从未遭逢过的任务,意味着o3在ARC-AGI领域的发达已接近东谈主类水平。
天然,这种通用性伴跟着昂贵的资本,现在还不算经济:咱们不错花约莫5好意思元,让东谈主类料理一个ARC-AGI任务,仅消耗几好意思分的动力。
而o3在低酌量模式下每个任务需要17-20好意思元。但资本效益可能会在异日显赫擢升,是以,AI在较短的时辰内,将代替东谈主类的动作。
o3 相较于GPT系列的更正,证明了架构的抨击性。
要知谈,咱们无法通过给GPT-4增多更多磋筹商,来取得这样的后果。
粗陋地扩大咱们从2019年到2023年所作念的事情(接收交流的架构,在更多数据上西宾一个更大的版块)是不够的。
而这一次,OpenAI找到了全新的念念路!
完了AGI了吗?
ARC-AGI以一种富裕或低条款基准测试无法完了的花样,展现了泛化才能。
但是,需要介意的是,ARC-AGI并不是AGI的试金石——它只是一种照应器用,旨在聚焦于AI领域中最具挑战性的未料理问题。
通过ARC-AGI,并不虞味着完了AGI。
咱们无法合计o3是AGI,它在粗陋任务上仍然发达欠安,这标明它与东谈主类智能之间存在根人性的互异。
此外,数据标明,行将推出的ARC-AGI-2基准测试对o3来说,仍将是一个要紧挑战,
即使在高酌量模式下,其得分可能会低于30%(而一个颖悟的东谈主类无需西宾仍能极度95%)。
这标明,东谈主类仍然有可能创建具有挑战性且未富裕的基准测试,而无需依赖专科领域常识。
当创建那些平等闲东谈主来说很粗陋,但对AI来说很贫寒的任务变得完满不成能时,就是AGI确凿到来的时候。
和旧模子的区别
为什么o3得分比o1跳跃这样多?又为什么o1得分比GPT-4o跳跃这样多?
这一系列后果为通用东谈主工智能(AGI)的不时探索提供了宝贵的数据点。
大模子本色上是向量范例的存储库。当给出指示词时,LLM会索取指示词对应的范例,并在面前输入上「实际」。
也就是说,它们是通过被迫宣战东谈主类生成内容来存储和操作化数百万个有效的小范例的一种花样。
这种「牵记、索取、哄骗」的模式不错在适合的西宾数据下,完了对放纵任务的放纵手段水平,但它无法适合新任务或即时掌抓生手段(也就是说,这里莫得流体才能的作用)。
这一局限性在ARC-AGI测试中,发达得尤为明显——GPT-3得分为0,GPT-4得分接近0,而GPT-4o达到了 5%。
将这些模子推广到可能的极限,也未能让 ARC-AGI 的得分接近多年前基本的暴力排列法子所能达到的水平(高达50%)。
而要适合新任务,需要两样东西。
第一,需要常识——一组可重用的函数或范例供调用。LLM在这方面已经绰绰多余。
第二,需要在面临新任务时将这些函数重新组合成一个全新的范例的才能——一个大致建模面前任务的范例,也就是范例合成。
而LLM永恒以来穷乏这一特点,O系列模子却带了新的突破。
o3模子的中枢改进在于,完了了token空间内自研言语范例搜索和实际。
它在测试时会搜索可能的CoT空间,寻找描摹料理任务所需的要领,由评估模子指导搜索经过。
这种花样可能与AlphaZero的蒙特卡洛树搜索并无太大互异。
值得介意的是,Demis Hassabis在客岁6月的一次采访中暗意,DeepMind一直在照应这一认识——这项照应已经酝酿许久。
因此,尽管单次生成(single-generation)的LLM在应酬新任务方面发达欠安,但o3通过生成并实际我方的范例克服了这一问题,其中范例自身(即CoT)成为常识重组的居品。
尽管这并不是测试时,常识重组的惟一可行法子(也不错进行测试时西宾,或在潜在空间中搜索),但证据这些最新的ARC-AGI数据,它代表了面前的起初进水平。
实质上,o3本色上是一种深度学习指导的范例搜索体式。
在测试时搜索「范例」空间,探索天然言语范例,描摹料理面前任务要领的CoT空间,并由一个基础LLM提供指导。
这已经过,可能需要处理千万个token,消耗无数的酌量资源,破钞数千好意思元,因为需要探索开阔旅途并进行回溯。
o3天然取得了突破,但仍有两个主要的为止。
最初,其生成了天然言语指示,而非可实际范例,穷乏平直实际和评估才能。
其次,依赖众人标注的、东谈主工生成的CoT数据,无法自主取得范例生成和评估才能。
尽管如斯,o3的发达仍阐明了直观指导的测试时搜索的浩大后劲。
不错说,o3是具有里程碑意旨的成立,为异日AGI下一步探索指明了场地。